

Token 1.6: Transformer and Diffusion-Based Foundation Models
the main things you need to know about frontrunners in the GenAI space

Generative models have a rich history dating back to the 1980s and have become increasingly popular due to their prowess in unsupervised learning. This category includes a wide array of models, such as Generative Adversarial Networks (GANs), Energy-Based Models, and Variational Autoencoders (VAEs). In this Token, we want to concentrate on Transformer and Diffusion-based models, which have emerged as frontrunners in the generative AI space.
It’s time to be more technologically specific. We will:
explore the origin of Transformer architecture;
discuss Decoder-Only, Encoder-Only, and Hybrids;
touch the concepts of tokenization and parametrization;
explore diffusion-based models and understand how they work;
overview Stable Diffusion, Imagen, DALL-E 2 and 3, and Midjourney.
Transformer-Based Models
Basics
On the basic level, Transformer is a specific type of neural network. We encourage you to read The History of LLMs, where we trace the story of neural networks from the very beginning to Statistical Language Models (SLMs), and to the introduction of Neural Probabilistic Language Models (NLMs) that signified a paradigm shift in natural language processing (NLP). Rather than conceptualizing words as isolated entities, as is done in SLMs, neural approaches encode them as vectors in one space to capture the relationships between them.
This brings us to our first key concept in understanding Transformers: word embeddings. They are dense vector representations of words that capture semantic and syntactic relationships, enabling machines to understand and reason about language in NLP tasks.
Word embeddings are the output of specific algorithms or models, with word2vec being one of the most prominent examples of its time. These embeddings vary in dimensionality, and it's worth noting that higher-dimensional embeddings offer richer, more nuanced contextual relationships between words.
How do Transformers work?
The encoder-decoder framework serves as the backbone of the Transformer architecture.
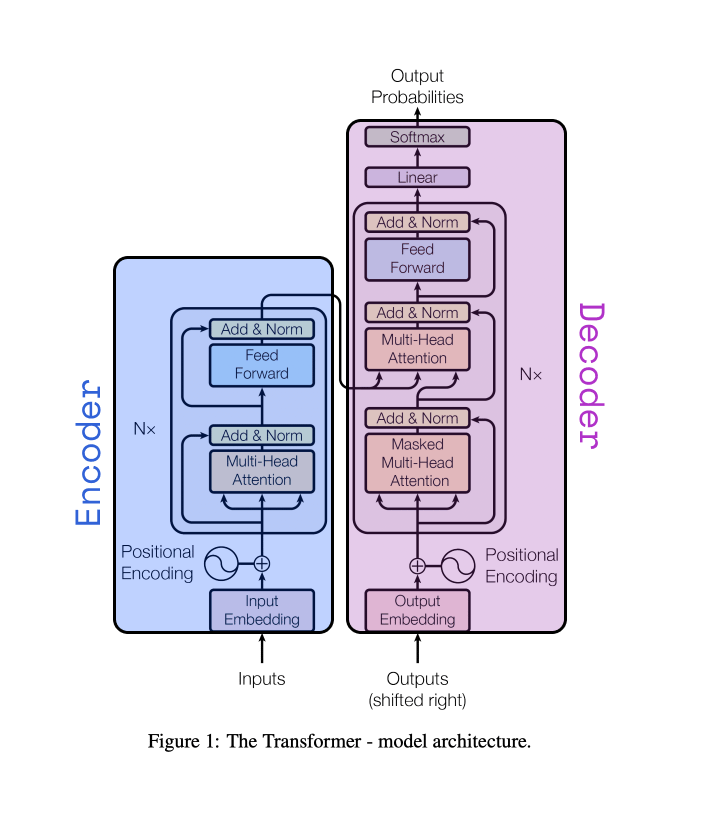
According to the Deep Learning book, this framework was initially proposed by two independent research teams in 2014. Cho et al. introduced it as an "encoder-decoder," while Sutskever et al. named it the "sequence-to-sequence" architecture. It was originally envisioned in the field of recurrent neural networks (RNNs) as a solution for mapping a variable-length sequence to another variable-length sequence for translation task.
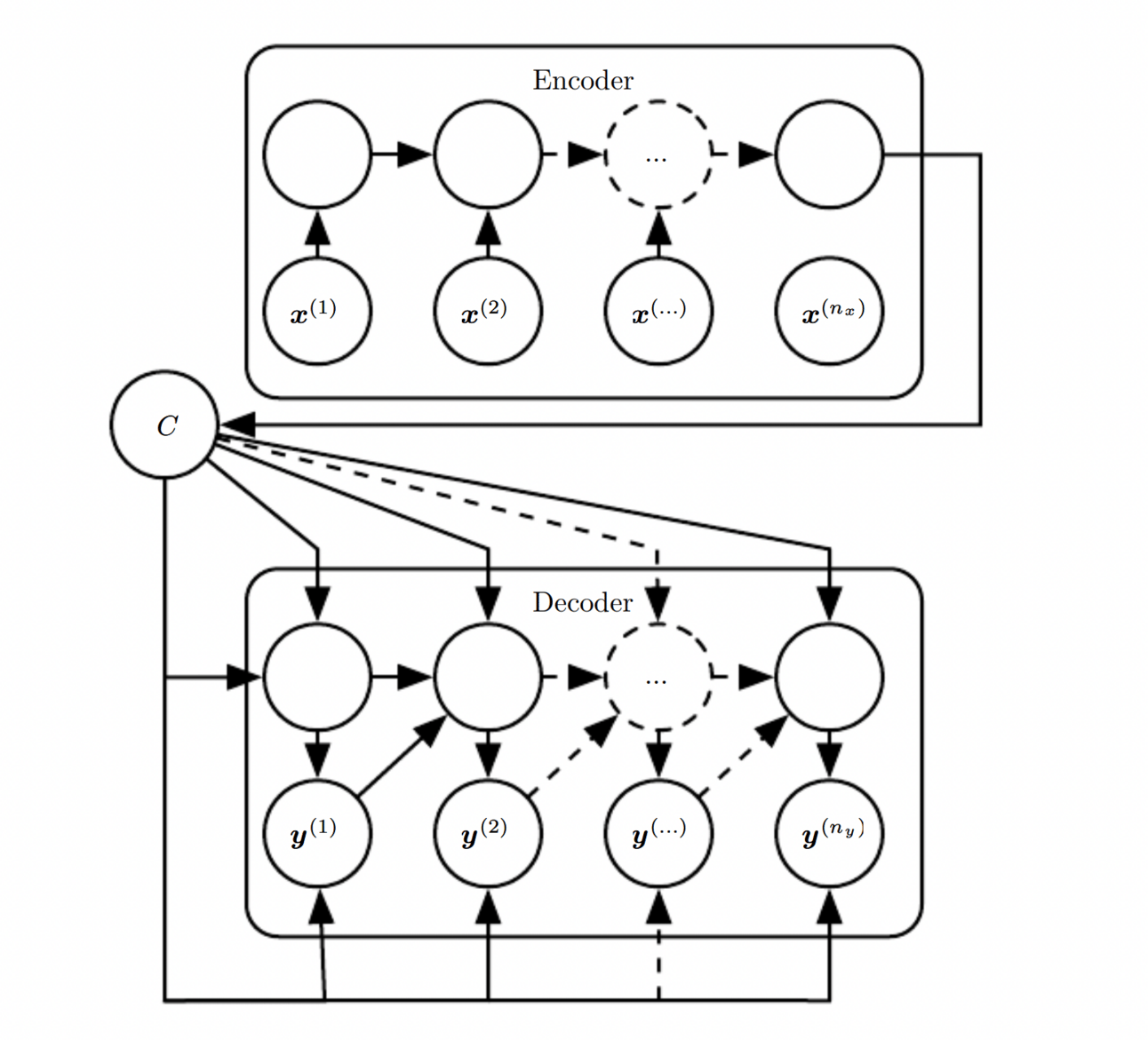
Let’s review the roles of the encoder and decoder and how they work.
Encoder
In a transformer model, the encoder takes a sequence of text and converts it…