

State of AI Coding: Context, Trust, and Subagents
Emerging playbook beyond IDE
If you are using IDE by January 1 – you are a bad engineer!
Steve Yegge, Sourcegraph, ex-Google, ex-Amazon, self-acclaimed AI babysitter
Two days at the AI Engineer Code Summit in NYC (Nov 20-21) felt less like a conference and more like a working prototype of 2026. And if I have to point out one thing it would be this:
2026: The Year the IDE Died
That was literally the title of Steve Yegge and Gene Kim’s talk. And while we’ve heard predictions about the “death of the IDE” before, what should we do about it, actually?
What we’re witnessing is a structural change in how engineers think about coding when the coder is no longer a person typing into a buffer. In a sense, the industry that builds software is shifting to a new set of physics: from hands-on human to physics of a distributed system of autonomous workers operating inside verification chains. So what becomes the role of the human? And what kind of system can we trust to build the software we rely on?
This article is an attempt to draw a map that emerged from those two days. If you believe a bigger model will save you, you are thinking about this moment the wrong way. But how to think about it? Let’s discuss the systems that will build the software of the future.
In today’s episode:
What actually changed: from “The Diver” to “The Ant Swarm”
Context engineering: the discipline everyone now practices
Verification as the real moat
The rise of parallel agents and the orchestrator class
Artifacts replaced chat
The struggles are real
The emerging playbook and the new agentic coding stack
Final thought
Resources
What Actually Changed: From “The Diver” to “The Ant Swarm”
Steve Yegge from Sourcegraph has so many bangers and sharp metaphors that I have to use him again. His framing of “an ant swarm” versus “a diver in the ocean” is a great explanation of why scaling the window doesn’t solve the underlying problem:
“Your context window is like an oxygen tank. You’re sending a diver down into your codebase to swim around and fix things for you. One diver. And everyone says: we’ll just give him a bigger tank. One million tokens. But he’s still going to run out of oxygen!”
No matter how big the tank is, a single agent deep in the weeds eventually suffers from what might be called “nitrogen narcosis” – it loses the thread, hallucinates interfaces, and forgets the original goal. Very familiar, right?
Later Dex Horthy from HumanLayer gave it another catchy name – “Dumb Zone”. He presented findings from 100,000 developer sessions identifying what he calls the – getting past the middle 40-60% of a large context window where model recall degrades and reasoning falters. “The more you use the context window, the worse outcomes you get,” Horthy warned.
So “God Model” approach is dead. You cannot prompt your way out of the Dumb Zone.
What can you do?
Context Engineering: The Discipline Everyone Now Practices
The winning architecture is the “Ant Swarm” or “Agent Swarm”, that operate like factories. As an example:
The Planner Ant: Reads the issue and writes a spec.
The Research Ant: Greps the repo, reads 5 relevant files, and extracts interfaces.
The Coder Ant: Implements the function in a clean, isolated context.
The Tester Ant: Runs the build and reports the outcome.
Why this matters: This approach solves “Context Pollution.” By giving each “ant” a blank slate for its specific task and only returning key information, we avoid filling up the orchestration agent with what can ultimately be distracting information, and we might be able to avoid Horthy’s “Dumb Zone” entirely.
This reframes the engineering discipline. Your job is no longer coaxing clever behavior out of a single model (it’s impossible!). Your job is Architecting the Ant Farm – building the clean, deterministic, well-instrumented environment where a swarm of specialized agents can operate without crashing into each other.
So yes, if last year was the year of prompt engineering, this year is the year of context engineering and context management.
The only way to get better performance out of an LLM is to put better tokens in, and then you get better tokens out. Every turn of the loop, the only thing that influences what comes out next is what is in the conversation so far.
Dex Horthy, HumanLayer
But “better tokens” doesn’t mean “more tokens.” It means Intentional Compaction.
The most effective teams are now adopting the RPI Loop (Research-Plan-Implement) to systematically avoid the Dumb Zone. It works by forcing a hard stop between thinking and doing.
Research: An agent scans the codebase. It does not write code. It produces a compact markdown summary of only the relevant state.
Plan: A reasoning model (or a human) reviews the research and writes a step-by-step plan. This plan compresses “intent” into a clean artifact.
Implement: A separate agent executes the plan with a fresh, empty context window.
It means building what the OpenAI Fine-Tuning team call “The Harness” – a rigid architectural scaffold that forces the model to behave. Call it “Harness Engineering” if you wish, and it means – deliberately making the process slower and harder to ensure the context stays pristine.
Others echoed similar patterns. Beyang Liu from Amp Code described the same failure mode through the lens of tool overload: “Context confusion. The more tools you add in the context window, the more things the agent has to choose from. If the tools are not relevant to the task at hand, it ends up getting confused.”
At Anthropic, Katelyn Lesse showcased how they are productizing this discipline via Memory and Context Editing. They are giving developers tools to explicitly “prune” the context window – deleting old tool outputs and irrelevant files – to keep the model’s IQ high. The era of “just dump the whole repo into the prompt” is officially over.
DO NOT OUTSOURCE THE THINKING. It can only amplify the thinking that you’ve done.
Dex Horthy, HumanLayer
Use the RPI loop to force the agent to prove it understands the context before it writes a single line of code. If you skip the Research phase, you are diving straight into the Dumb Zone. That’s not what you want.
The Rise of Parallel Agents and the Orchestrator Class
If humans are unitaskers – capable of focusing on only one thread at a time – agents are fundamentally parallel.
But the current generation of AI tools (think ChatGPT or GitHub Copilot) honors this human limitation. They are reactive. You sit in front of a chat box, type a command, wait for the spinner, read the code, and prompt again. The AI is faster than you, but it is still locked to your linear timeline. You are the bottleneck.
The next generation, exemplified by Kath Korevec from Google’s Jules and new architectures from Replit, is breaking this linearity. They are moving from reactive assistants to proactive, asynchronous swarms. The word “Parallelism” was used a lot.
Imagine this scenario: You leave work at 6 PM. While you sleep, an agent named Jules observes that your dependencies are outdated. It spins up a workspace, reads the changelogs, updates package.json, runs the build, fixes three breaking changes, runs the test suite, and leaves a verified Pull Request waiting for you with a summary of its decisions.
This shift from “chatting” to “dispatching” unlocks true parallelism. Michele Catasta from Replit explained how they are moving toward a world where the primary interface is an orchestrator loop. It dispatches tasks to sub-agents that run concurrently. He described the initially generated interfaces as having a lot of “painted doors” — on first glance it looked good but more than 30% of the functionality wasn’t there, and the proactive agents can make sure these tasks aren’t forgotten. While one agent is refactoring the database schema, another is updating the frontend types to match, and a third is writing the documentation.
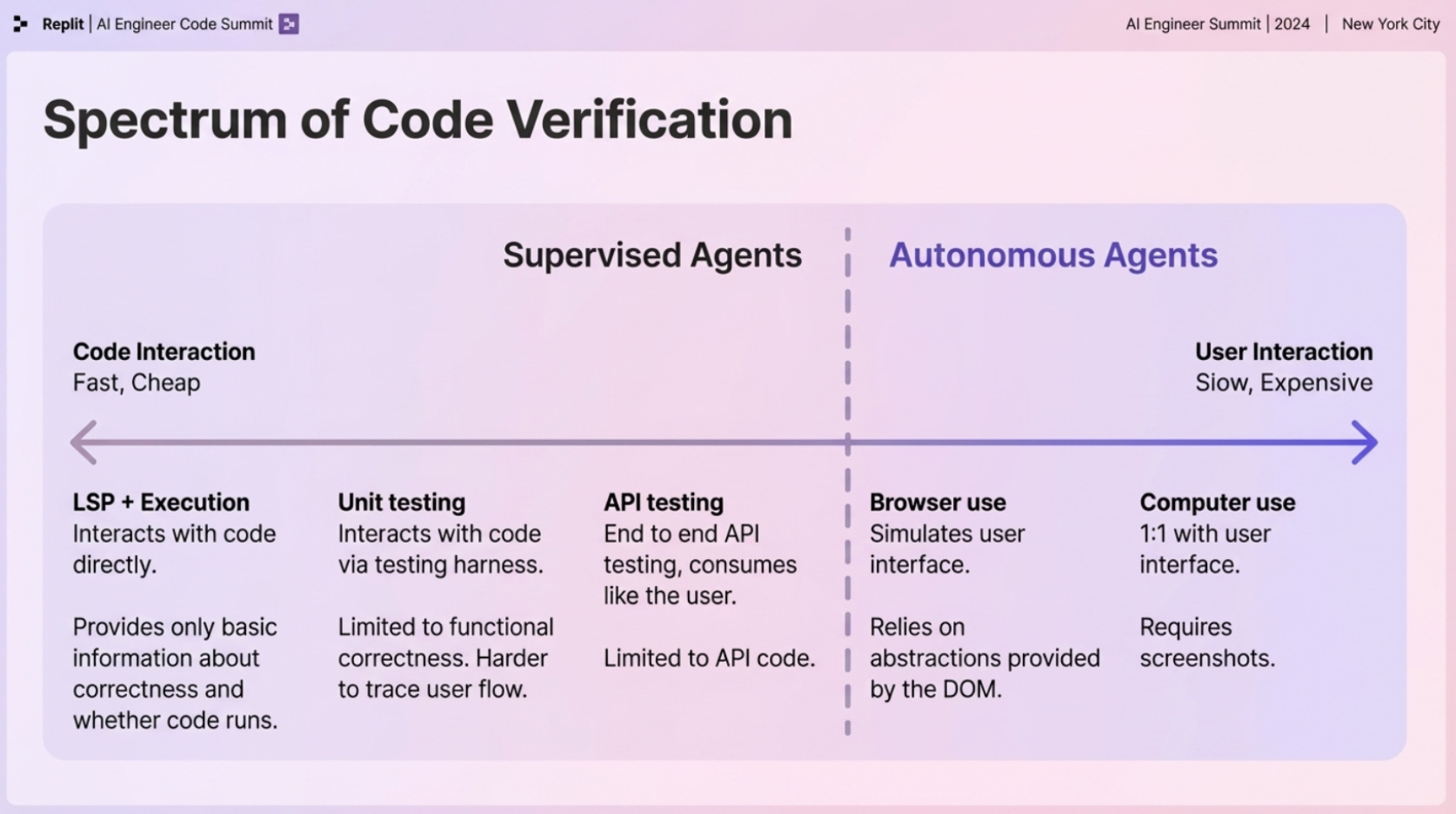
And you become this Orchestrator. But your job is not to write the loop; it is to define the constraints. You review the plans. You verify the the tests. You merge the work. The skill set shifts from syntax recall to systems thinking. Can you define the boundaries of a task clearly enough that a swarm can execute it without crashing into each other?
This is the new leverage. A senior engineer used to be 10x more productive than a junior because they could type the right solution faster. In the Orchestrator era, a senior engineer is 100x more productive because they can effectively manage a swarm of twenty agents working in parallel, while the junior eng is still stuck chatting with one.
I resonate with what you wrote about the structural shift, and I'm particularly keen to understand the practical distinction you draw between "context engineering" and the broader implications of "verification as a service" within this new phisics of distributed autonomous systems.