



FOD#95: Llama. Kind AI. And Landscape of Foundation Agents
Our Research recommendation section is back!

1. Llama 4: Meta's Surprising New AI Models and Mixed Reception
Meta made a splash on April 5, 2025, unexpectedly releasing a whole herd of new Llama models on a Saturday, igniting initial excitement followed by a harder wave of criticism. Their new models are:

The most significant architectural innovation is the adoption of a mixture-of-experts (MoE) approach, where only a fraction of the model's parameters are activated for any given input. This allows for massive total parameter counts while keeping computational requirements manageable.
Initial Disappointment in Performance
Many users have expressed significant disappointment with Llama 4's actual performance, particularly in coding tasks. Dr. Kaminski on Reddit noted:
"I just finished my KCORES LLM Arena tests, adding Llama-4-Scout & Llama-4-Maverick to the mix. My conclusion is that they completely surpassed my expectations... in a negative direction."
The disappointment is particularly acute given the models' size. According to DRMCC0Y on Reddit: "In my testing it performed worse than Gemma 3 27B in every way, including multimodal. Genuinely astonished how bad it is."
Despite Maverick having 402 billion parameters, many users found it performing on par with much smaller models like Qwen-QwQ-32B.
Controversy Over Benchmark Claims
And then – benchmarks. The company showcased impressive results on the LMArena leaderboard for Llama 4 Behemoth – the model that isn’t publicly available and still in training. This discrepancy has damaged trust and led to accusations of misleading marketing.
As noted by Nathan Lambert in his analysis: "Sneaky. The results below are fake, and it is a major slight to Meta's community to not release the model they used to create their major marketing push."
Hardware Limitations and Context Window Reality
Despite claims of a 10 million token context window for Scout, current providers significantly limit this in practice (to around 128,000-328,000 tokens depending on the provider). Additionally, the MoE architecture makes these models challenging to run on consumer hardware – even with 4-bit quantization, the 109B Scout model is "far too big to fit on a 4090 – or even a pair of them," according to Jeremy Howard.
Why the Disappointment?
Several factors may have contributed to Llama 4's underwhelming reception:
Rushed Release: The unexpected Saturday release and reports of internal "war rooms" at Meta suggest competitive pressure, particularly from Chinese models like DeepSeek's R1.
Architectural Trade-offs: While the MoE architecture enables massive parameter counts, it introduces complexity that may affect performance consistency if not perfectly tuned.
Misaligned Strategy: The focus on ultra-large models doesn't serve the open-source community's needs for efficient, accessible implementations that can run on consumer hardware.
License Restrictions: The increasingly restrictive Llama license, including EU exclusion and commercial usage limitations, has alienated parts of the open-source community. (DeepSeek, for example, has a much more permissive license).
Some excitement is coming from Hugging Face (where you can try Llama) and, of course, Meta:

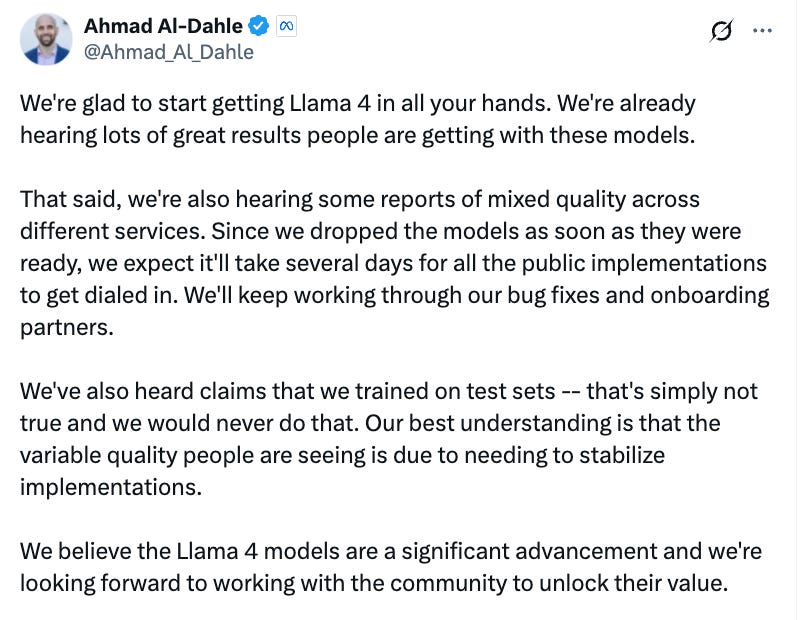
Fresh clarification from GenAI Lead @ Meta
There’s a huge difference between the earlier Llama releases and this current flop. The competition in the “open-source” space is fierce now – DeepSeek, Gemma, Mistral, QwQ – all delivering better results with much smaller models. Meta’s strategy feels completely convoluted, probably driven by newly adopted masculine energy from Mark Zuckerberg that requires beating everyone in benchmarks forgetting about what made Llama popular in the first place.
Meta, in trying to dazzle with size and swagger, may have built a herd for a wrong pasture.
2. Kind AI
After that snappy ending let’s talk about kindness. Last week, Google DeepMind published a very interesting paper "An Approach to Technical AGI Safety and Security", that discusses:

They say “We are highly uncertain about the timelines until powerful AI systems are developed, but crucially, we find it plausible that they will be developed by 2030.” They also reference "Position: Levels of AGI for Operationalizing Progress on the Path to AGI". Looking at the levels, I wondered why we never speak about kindness in AI.
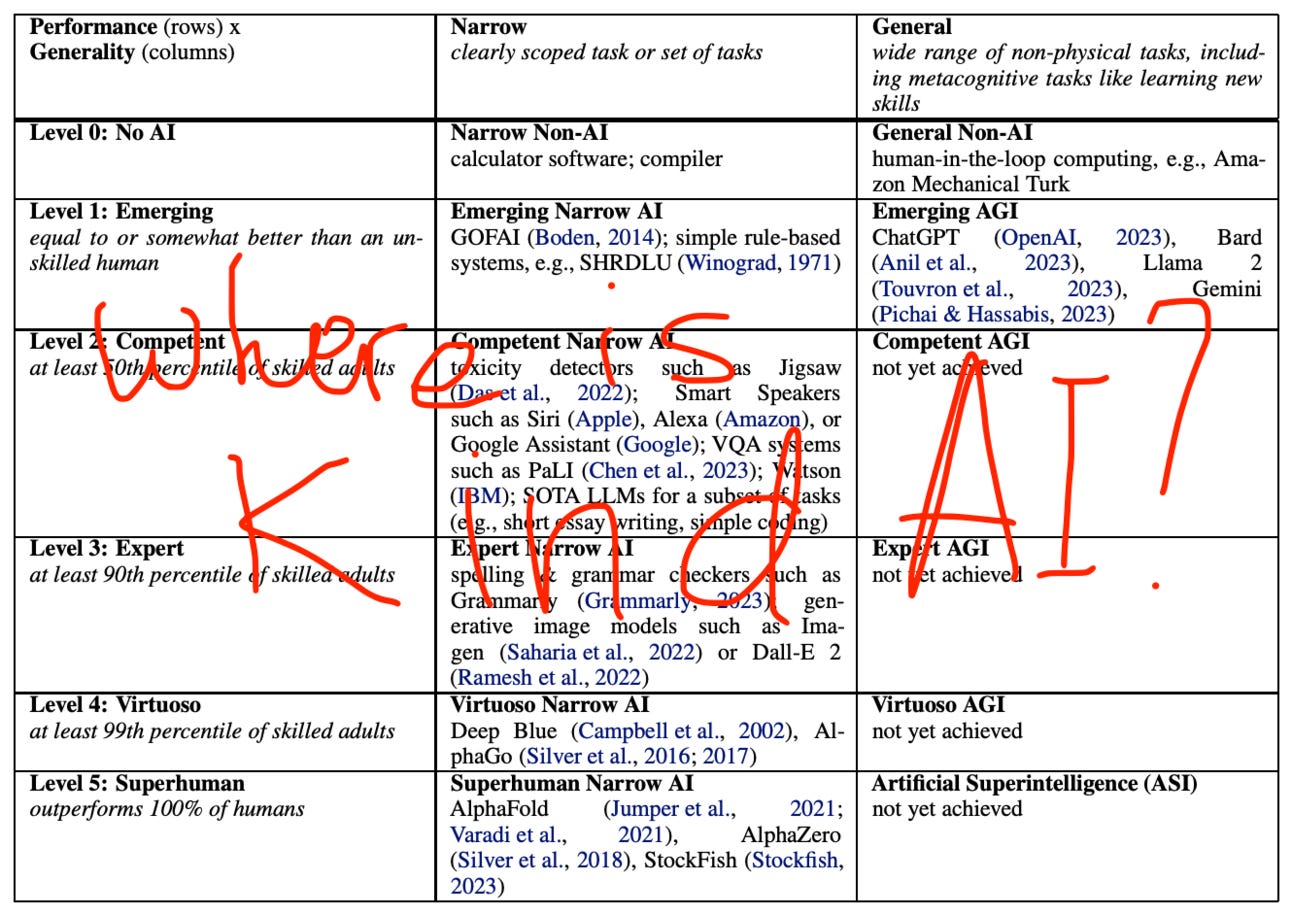
It would be funny to turn the narrative around, and instead of AGI, start discussing KAGI – Kind Artificial General Intelligence. Yes, ChatGPT/Claude/Gemini etc are trained to refuse harmful instructions and respond with civility and care. But why don’t we use the word “kind” more?
I looked it up, by the way – 鍵 (Kagi) means "key" or "lock" in Japanese. Symbolically, keys represent security, secrets, or unlocking hidden potential. Kagi often represents opening or closing spiritual gateways; access to hidden or mystical knowledge – definitely the things that I would like my AI to do. Just some food for thoughts.
3. Advances and Challenges In Foundation Agents
20 prominent research labs got together and published a 264-page survey that is basically a deep dive into how we’re building super-smart AI agents. They are trying to answer the big questions like, "How close are these things to actually thinking or acting like humans?" and "What are they currently capable of, what's still tricky, and how do we make sure they don't go rogue?"
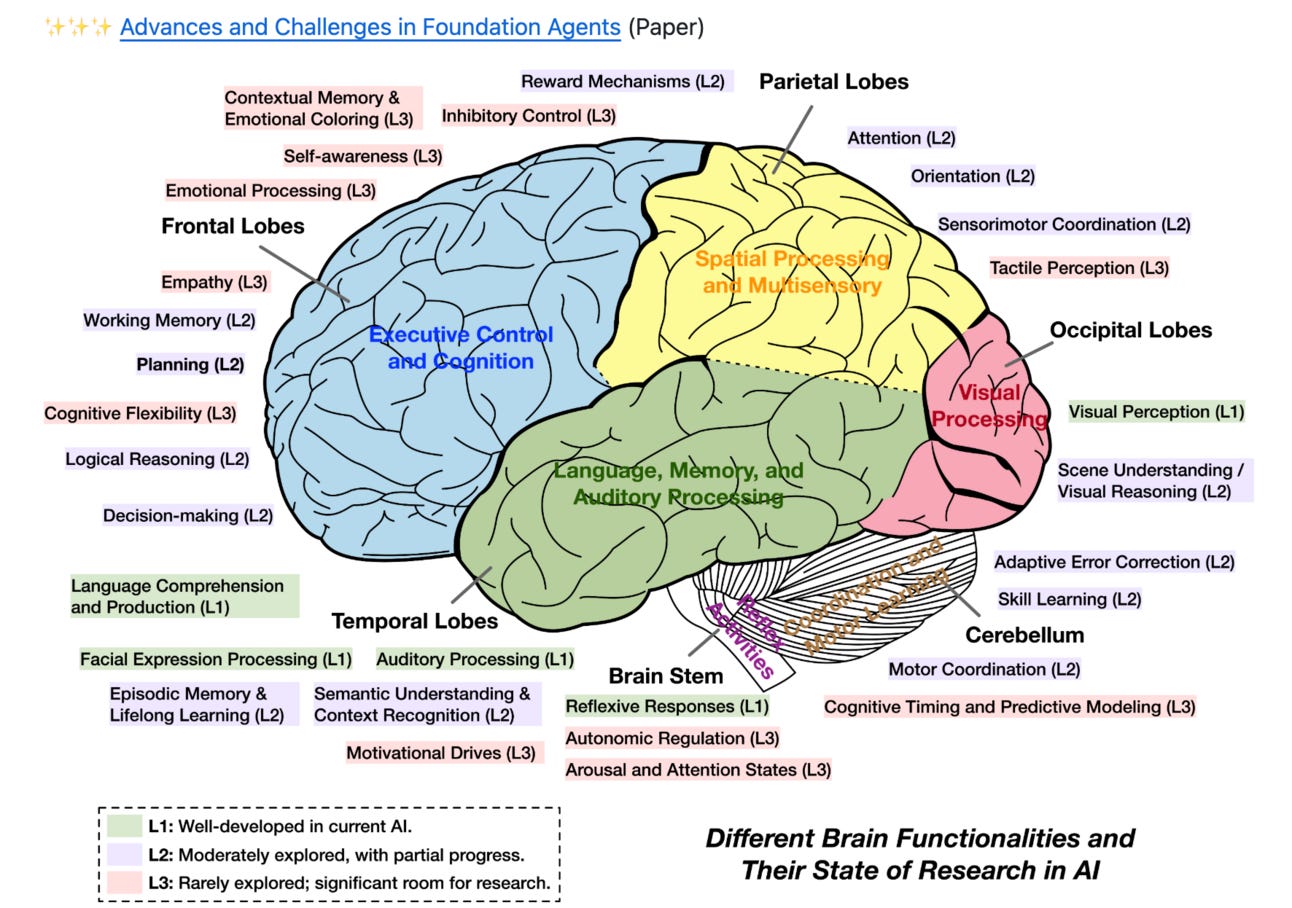
If you're curious about where AI is headed beyond just chatbots – like AI that can plan, remember things long-term, use tools, learn on its own, and even work in teams – this survey will be of interest. It connects the AI stuff to how our brains work. Plus, it covers the super important angle of how to build these things safely and ethically. Do they operate the term “kind” – no, they don’t, but nonetheless, it’s a solid read.
Welcome to Monday. Or as AI labs call it now: Surprise Release Recovery Day.
Curated Collections

We are reading/watching
2027 Intelligence Explosion: Month-by-Month Model — Scott Alexander & Daniel Kokotajlo at Dwarkesh Patel’s Podcast
Jorge Luis Borges’s and Herbert A. Simon’s understanding of free will
Co-Agency as The Ultimate Extension of Human (we open our last article for all readers)
News from The Usual Suspects ©
Demis Hassabis’s Isomorphic Labs has raised $600 million in its first external funding round, led by Thrive Capital with GV and Alphabet joining in. The DeepMind-born biotech firm is pushing its AI drug discovery engine closer to clinical impact, with programs spanning multiple therapeutic areas.
Genspark – new cool AI kid on the block – has launched Super Agent, a new entrant in the increasingly crowded world of autonomous AI agents. With orchestration across 9 LLMs and 80 tools, the system executes complex real-world tasks – from trip planning to synthetic voice calls. It edges past competitors on the GAIA benchmark, raising the bar for task automation. It works pretty well.
OpenAI’s PaperBench – their new evaluation suite, challenges AI agents to replicate ICML papers from scratch – no code given. Claude 3.5 Sonnet tops the leaderboard but still scores just 21%. Even the best models falter at long-horizon reasoning and execution, reminding us that real research isn't easily outsourced.
DeepMind’s Dreamer, its latest reinforcement learning agent, has successfully collected diamonds in Minecraft without human demonstrations. It does so by imagining future actions through a learned world model. A small task with big implications: generalisation and planning in novel environments.
Anthropic announces Claude for Education, launching AI access across Northeastern, LSE, and Champlain College. A new “learning mode” shifts Claude from answer engine to reasoning coach, while partnerships with Internet2 and Canvas aim to integrate AI into academic workflows – thoughtfully and at scale.
Models to pay attention to:
HallOumi (Oumi AI) – open-source 8B model for claim verification and hallucination detection. Outperforms top models with sentence-level citations, scoring, and explanations. Includes classifier variant and custom benchmark →read their blog
ScholarCopilot – a retrieval-aware LLM fine-tuned on 500K arXiv papers. It dynamically retrieves citations mid-generation to enhance academic writing, outperforming much larger models like Qwen-2.5-72B in citation and coherence metrics →read the paper
🌟Command A (Cohere) – is an enterprise-optimized LLM trained for RAG, tool use, and multilingual capabilities (23 languages). Uses decentralized training, agent optimization, and novel model merging techniques →read the paper
OThink-MR1 – a multimodal LLM enhanced with Group Relative Policy Optimization (GRPO-D) for general reasoning across tasks. Shows significant cross-task generalization over SFT models →read the paper
RIG – an end-to-end generalist policy model for embodied agents that synergizes reasoning and imagination to achieve 17x sample efficiency →read the paper
Z1 – a code-reasoning-optimized LLM designed to reduce "thinking token" overhead via efficient trajectory training and the Shifted Thinking Window mechanism →read the paper
🌟TransMamba – a hybrid sequence model unifying Transformer and Mamba with shared parameter matrices. Dynamically switches mechanisms depending on sequence length →read the paper