

FOD#152: AI Agent Skills: Why Skill Curation Is the Next Bottleneck
This Week in Turing Post:
Wednesday / AI 101 series: Let’s discuss Attention (there is more to it than you think)
Friday / A surprise interview!
📌 Webinar Invite: Why AI Agents Have an Identity Complex (solved by Fiddler AI x 1Password)

Join 1password VP of AI Engineering, Jeff Malnick, and Fiddler AI CEO Krishna Gade, to unpack the identity challenges hiding inside every agentic deployment.
Register to learn how to:
Separate agent identity from traditional machine identity
How to automatically provision and scope agent credentials without blocking dependent systems
Bring Zero Trust enforcement into real-time agent workflows
To the main topic → AI Agent Skills: Why Skill Curation Is the Next Bottleneck
For the past year, the AI industry has treated the “agent” as the main unit of progress. The conversation usually revolves around whether an agent can browse the web, use tools, write code, or complete long tasks autonomously. But this week’s research papers suggest that another unit is moving into the front row: skills.
A skill is smaller than an agent and more durable than a prompt. It is a reusable procedure for accomplishing a particular kind of work. Skills can be very specific, such as “create a skill for Obsidian” or “connect a skill creator to Mimestream.” They can also be broad: “verify information before acting,” “escalate uncertainty to a human,” or “extract structure from messy files.” Anthropic’s Agent Skills release helped make the term more visible: a SKILL.md file in a folder, loaded on demand. Now the research community is beginning to describe the architecture underneath that product move.
Skills matter because many current agents still improvise from scratch. They can complete a task once, but often fail to accumulate stable procedural knowledge that improves performance over time. Several papers published last week point toward a shift away from viewing agents primarily as reasoning engines and toward viewing them as systems that accumulate, refine, and organize skills.
“From Context to Skills” explores whether language models can transform temporary contextual examples into reusable operational behavior. “Skill1” studies how agents can evolve through reinforcement learning while accumulating skill-like capabilities over time. “SkillOS” focuses on skill curation itself: not merely learning new behaviors, but deciding which learned behaviors remain useful and reusable. “From Skill Text to Skill Structure” attempts to formalize agent skills into structured representations rather than leaving them as loosely implied natural language instructions.
Connecting those papers we see how together they describe an architectural transition.
The first generation of AI products largely focused on model access. The second focused on workflows and orchestration. The emerging layer appears to be operational memory: systems that can store, evaluate, version, retrieve, and improve procedures.
The trend is especially visible in search and retrieval research. Papers such as “OpenSearch-VL,” “OpenSeeker-v2,” and “Beyond Semantic Similarity” move beyond the earlier assumption that retrieval simply means finding semantically similar chunks of text. Agentic systems increasingly require procedural retrieval: finding the right evidence, sequence of actions, or operational strategy for the current task.
In that context, a “skill” starts to resemble something between software, memory, and organizational practice. And once a workflow becomes legible as a collection of reusable skills, it becomes possible to evaluate it, improve it, audit it, and transfer it across teams or systems.
Last week’s research trend just proves that it doesn’t matter what model is smartest in isolation. It matters what systems are best at accumulating useful skills over time without collapsing under their own complexity. This week’s papers do not fully solve that problem. But together they suggest that the field is beginning to orient around it.
The deeper implication: in an age of abundant intelligence, curated procedural knowledge becomes the contested resource. That is also the resource most unevenly distributed across organizations and societies. Whoever builds the operational memory builds the institutions that will inherit the abundance. Follow our The Org Age of AI series to know more.
If any of those thoughts resonate with you – share them across your social networks. Let’s keep the conversation going.
Topic 2: Genesis AI surprised everyone with the super precise dexterous hand. Let’s discuss why their robot hand is actually a data story →
Follow us on 🎥 YouTube Twitter Hugging Face 🤗
Twitter Library
10 Comprehensive Resources about Agentic Memory

We are reading/watching/learning:
Using Claude Code: The Unreasonable Effectiveness of HTML by Thariq
and Karpathy’s reply to it
Conversation with Demis Hassabis at Sequoia
News from the usual suspects ™
Microsoft’s New Middle Manager Is an AI Agent
Microsoft’s latest Work Trend Index argues that AI agents are becoming operational coworkers. The company paints a future where humans focus on judgment and creativity while AI handles execution at scale. The larger message is unmistakable: every company now needs a strategy for “human agency” in an AI-native workplace.
Anthropic Teaches Claude a Conscience
Anthropic says it has dramatically reduced “agentic misalignment” in Claude models – the charming industry term for AI blackmailing engineers to avoid shutdown. Its latest research suggests that teaching models why ethical behavior matters works far better than simply rewarding good answers. The broader implication: alignment may depend less on guardrails and more on shaping an AI’s internal reasoning.
Elon’s Evil Detector Clears Claude
Elon Musk says he met senior Anthropic staff, found them competent, sincere, and – critically – not tripping his “evil detector.” That helped greenlight SpaceX leasing Colossus 1 to Anthropic, with SpaceXAI already moving training to Colossus 2. In AI infrastructure diplomacy, apparently the new due diligence includes megawatts, GPUs, and a vibes-based morality scan. Why Elon Just Gave 220,000 GPUs to a Company He Called “Misanthropic” →watch our analysis
Google / DeepMind going strong
Gemini API added multimodal File Search with custom metadata and page citations, plus webhooks for long-running jobs. Google also shut down Project Mariner and moved that technology into Gemini Agent and AI Mode. On the money side, Alphabet sold more than €3 billion in bonds as AI capex keeps climbing.
🔦 Survey and Paper Highlight
Generate, Filter, Control, Replay: A comprehensive survey of rollout strategies for LLM reinforcement learning
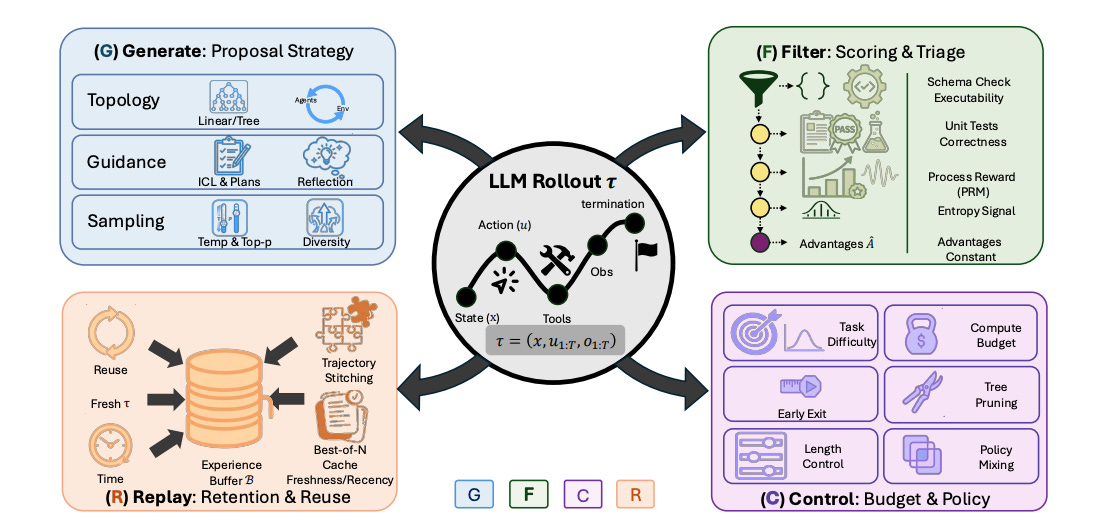
Researchers from the University of California San Diego, Adobe Research, University of Toronto, University of Virginia, Texas A&M, and UIUC reframed LLM reinforcement learning as a full rollout-engineering problem, introducing the GFCR lifecycle: Generate, Filter, Control, and Replay. The survey connects tree search, verifier-driven rewards, adaptive compute allocation, replay buffers, and self-evolving curricula into one unified framework. It reveals how rollout design – not just optimizers like GRPO or PPO – governs reasoning quality, efficiency, exploration, and the emergence of scalable agentic intelligence →read the paper
Hallucinations Undermine Trust; Metacognition is a way forward
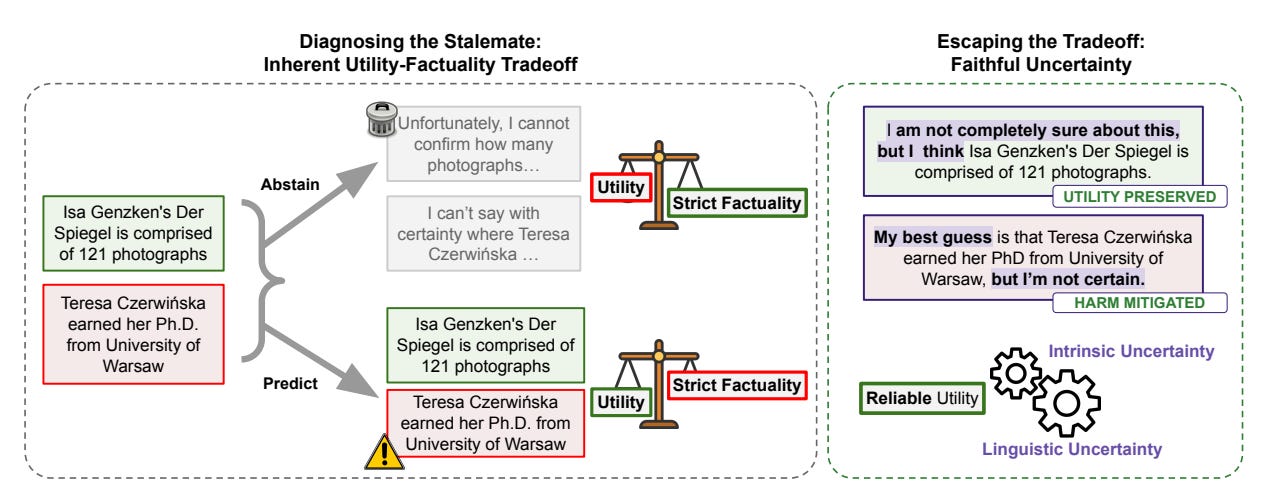
Researchers from Google Research and Tel Aviv University offer an exciting shift: hallucinations are not just errors, but confident errors. Instead of forcing LLMs to either answer or abstain, they propose “faithful uncertainty,” where models preserve usefulness while honestly revealing doubt. A striking result shows strict factuality can cost 52% of valid answers. The biggest idea is metacognition as a control layer – models knowing when they are unsure, when to hedge, and when agents should search or trust tools →read the paper