

FOD#141: What Happens to Software Engineering When Anyone Can Build?
the great split

This Week in Turing Post:
Wednesday / AI 101 series: The Evolution of AI Hardware: Taalas LLM-on-a-Chip
Friday / Interview with Ioannis Antonoglou is co-founder and CTO of Reflection AI
From our partners: Run AI Agents in Production Securely at Scale

Organizations are deploying AI agents across infrastructure, but legacy models weren’t built to scale with autonomous actors. Adopting an agentic identity framework provides a secure foundation for running agents in production, with identity-based access, short-lived credentials, and policy enforcement designed for non-human systems operating at machine speed. If you need to run AI agents securely and at scale, you should try this →
To the main topic: What Happens to Software Engineering When Anyone Can Build?
Last week, a few tremendously interesting blogs and articles landed on my screen. They were written in totally different contexts, by people who are not coordinating, and in some cases would probably disagree with each other in the comments.
But when I read them one after another, I saw a bigger picture so clearly that I’m rushing to share it with you.
AI writes code now. What interesting is the transformation of the coding profession. The trend I see is that software engineering is splitting into (at least) two disciplines at the same time:
Harness engineering: building the constraints, tools, feedback loops, and documentation that make agents reliable (the whole new industry right there).
Judgment manufacturing: growing humans who can direct, verify, and maintain agent-produced systems, especially early-in-career engineers.
Small note that matters: with agents, almost anyone can do a form of harness engineering. That doesn’t mean the software engineering profession goes away. It means exactly the opposite. Because while regular people will build lots of valuable “software” via harnessing, deep engineering remains essential when stakes go up: security, reliability, performance, compliance, messy integrations, and anything that can break in expensive ways.
You can absolutely harness-engineer your way to a working system. You can’t harness-engineer your way out of physics, adversaries, production entropy, and not fully understood agents (food for thought: a paper called “Agents of chaos”).
Now, let’s get to these articles and put the puzzle back together, so we can see the full picture.
The engineer’s job is turning into “environment + orchestration”
Charlie Guo’s “Harness Engineering” playbook is a good description of what serious teams are converging on: OpenAI reorganizing around agents, Stripe’s Minions producing a thousand merged PRs per week, solo builders running 5–10 agents in parallel and shipping code they don’t read line by line.
The model can write code – that’s a given now. The bottleneck becomes: does the environment make it hard to do the wrong thing and easy to do the right thing?
That’s harness engineering in one sentence.
After reading Guo’s post and also this tweet from Greg Brockman, I came up with the following repeatable pattern that might help while engineering:
Agent-first by default: stop opening the editor as step one. If you can write the task in 5–10 bullet requirements, hand it to an agent first. The agent drafts the plan and the PR; you focus on approving the plan and reviewing the diff.
Architecture as guardrails: constrain the solution space with strict boundaries and allowed dependency paths, enforced automatically with structural checks.
Tools as foundation + feedback: expose internal tools via CLI/MCP; run CI, lint, and tests with error messages that tell the agent exactly how to fix the failure.
Memory that compounds: treat AGENTS.md as the repo’s scar tissue. Every time an agent fails, write down what went wrong and how to avoid it; share the fixes as reusable templates, scripts, and tool configs across teams.
Plan-first discipline: don’t let the agent write code as the first move. Make it draft a plan, review it, approve it, then let it execute.
No slop policy: keep the merge bar unchanged. Every PR has a human owner, and reviewers understand what they’re signing off on.
Agent ops layer: run agents like production systems. Track their runs, centralize tool access, and turn recurring failures into harness improvements.
It’s both a workflow hygiene and an executable infrastructure. The agent is the worker. The harness is the factory. Your job is whatever the factory still can’t do: judgment, taste, accountability.
Bespoke software is real, and it’s going to explode demand
Andrej Karpathy posted a small anecdote that carries a large implication. He wanted a hyper-specific cardio experiment dashboard. No App Store category exists for “eight-week zone-2 plus HIIT treadmill tracker.” So he vibe-coded it in about an hour with an agent, including reverse-engineering a treadmill API, then debugging the usual jagged edges: unit conversion, calendar alignment.
His conclusion is the important part: the “app store” model feels outdated when an agent can improvise a tiny app for you on demand. The future is services, sensors, and actuators with AI-native ergonomics, stitched together into ephemeral software.
Andrew Ng makes the same point from economics: even if each developer becomes 10× more productive, we won’t need 1/10th the developers, because the demand for custom software has no practical ceiling. He’s already seeing early “X engineer” roles – like Marketing Engineer or Recruiting Engineer – people embedded in business functions who build software for that function.
Together this gives us a macro trend: Software turns from a set of packaged products into a continuous stream of bespoke tools.
I’m not even sure it’s Software 3.0. We are moving with such speed, that it might be Software 4.0 already. A redefinition of what “software industry” even means.
Rewriting gets cheap, so the software supply chain starts to change shape
Thomas Wolf zooms out another level: if rewriting and understanding foreign codebases becomes cheap, dependency trees stop looking like a superpower and start looking like a liability. Why keep a deep dependency tree if an agent can extract what you need or rewrite it cleanly? Fewer dependencies means a smaller attack surface, smaller packages, and often faster software.
Wolf then says the “Lindy effect” weakens. I’d phrase it a bit more precisely. Lindy isn’t “it exists for a good reason.” Lindy is a longevity heuristic: if something non-perishable has survived this long, it tends to keep surviving. In software, that survival advantage has been heavily propped up by a different force: replacement pain. Old systems stick because touching them is risky, expensive, and full of edge cases nobody wants to rediscover.
If agents change that, then the replacement pain drops. So legacy loses part of its moat, whether you call it Lindy or just switching costs plus fear.
Karpathy echoes this from a programming languages angle: translation is where LLMs are especially good, because the old code acts like a detailed prompt and a test oracle. It becomes plausible that we rewrite large fractions of existing software multiple times.
And that tees up the next trend: rewriting gets easier, but proving you didn’t break reality doesn’t.
Verification becomes the tax you can’t dodge
Wolf’s catch is the catch: unknown unknowns remain unknown. If you can rewrite everything, you also get to rediscover every weird edge case that the old system survived through sheer historical scar tissue.
So the question becomes: can we achieve complete coverage of testing, edge cases, and formal verification? In an AI-dominated world, Wolf argues formal verification stops being optional.
Guo’s piece points at the same hole from the operational side: functionally correct but poorly maintainable code creeping into codebases, agents marking work done without real end-to-end validation, retrofitting these workflows onto decade-old brownfield systems.
This is the new ground truth: agents multiply output faster than they multiply confidence. Harnesses help, but verification is still the bill that arrives at the end of the meal.
The hidden crisis: the entry-level pipeline collapses right when judgment matters most
Now connect all of this back to Russinovich and Hanselman’s CACM essay, which is the most direct “adults in the room” piece of the bunch.
Their point is simple: agentic coding assistants amplify senior engineers because seniors already have the judgment to steer, verify, and integrate what the agent produces. Early-in-career (EiC) developers don’t, so the same tools can slow them down or mislead them. The economic incentive that falls out of this is almost automatic: hire seniors, let agents swallow junior work.

And if that becomes the norm, the profession’s talent pipeline collapses. You don’t get the next generation of seniors by hiring them. You grow them.
Their proposed fix is an org design: preceptorship at scale. Pair EiCs with trained senior preceptors (3:1 to 5:1), for a year or more, and treat growth as an explicit organizational goal. They even suggest assistants should have an EiC mode that defaults to Socratic coaching instead of immediately generating solutions.
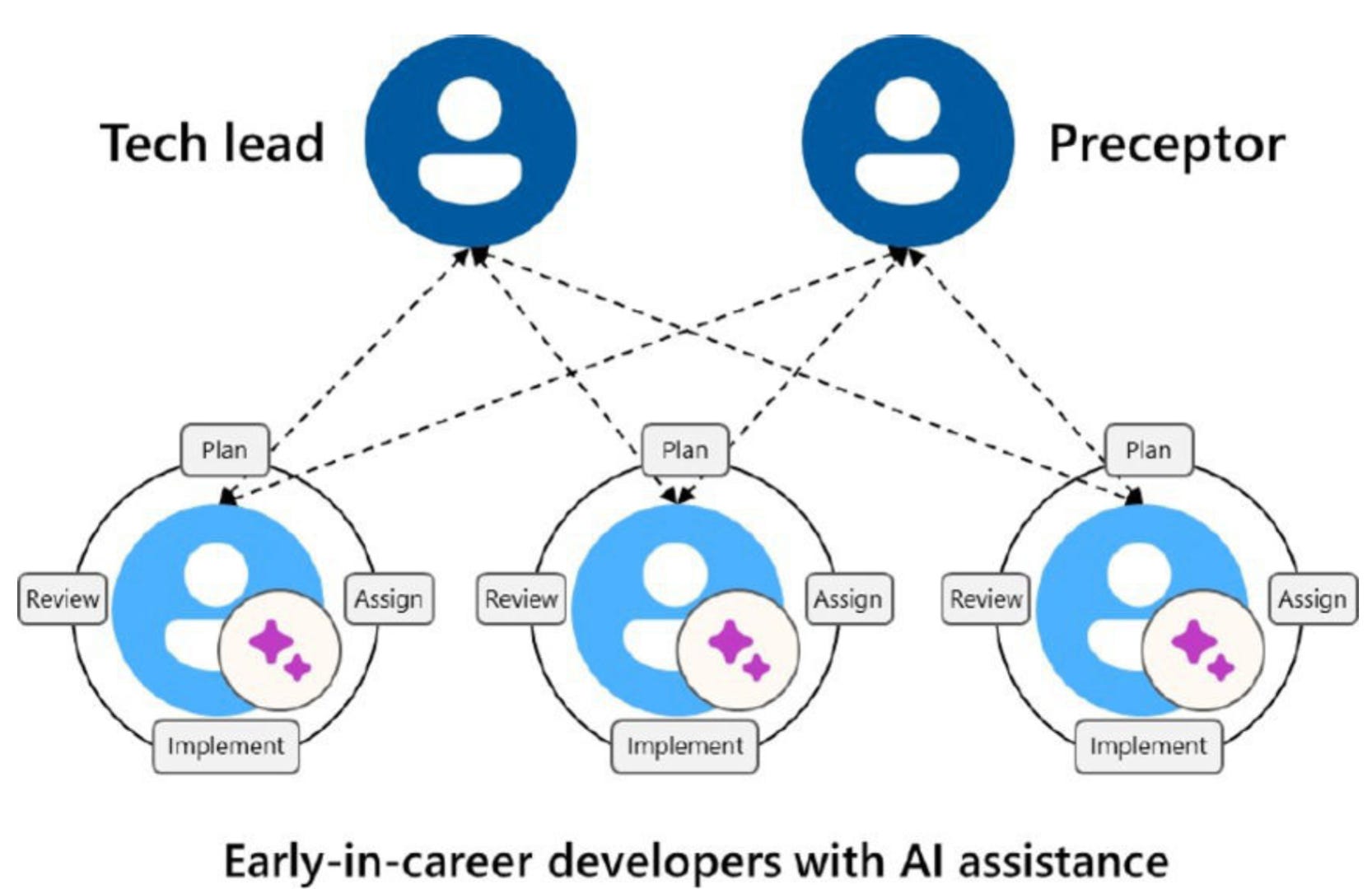
Put them together, and the picture is this:
We’re industrializing execution at neck-breaking speed. Judgment isn’t scaling with it, and it’s becoming the bottleneck.
Where this is heading
Over the next year, watch for three things:
Harness engineering becomes a real job title inside serious orgs, because “agent productivity” starts looking like a platform problem.
Bespoke software (Karpathy’s phrase) eats more of the world, which increases demand for people who can operate, integrate, and secure it.
The junior pipeline becomes a strategic risk. Teams that stop hiring and training early-career engineers will buy short-term throughput and accumulate long-term fragility.
Agents are turning software into an abundance business. The scarce resource is the human ability to decide what good looks like, prove it works, and keep it working.
If we don’t train that skill on purpose, we’ll ship more software than ever and end up in encoded chaos: code that passes automated checks, looks fine, and still breaks in the real world.
Our news digest is always free. Click on the partner’s link above to support us or upgrade to receive our deep dives in full, directly into your inbox. Join Premium members from top companies like Nvidia, Hugging Face, Microsoft, Google, a16z etc plus AI labs such as Ai2, MIT, Berkeley, .gov, and thousands of others to really understand what’s going on with AI → Upgrade
We are watching/reading:
Taalas and the Return of Model-Specific Computing. Will NVIDIA Buy Them? →watch here
OpenClaw Explained + lightweight alternatives (our latest hit)
Building Technology to Drive AI Governance by Jacob Steinhardt
China’s Compute Year in Review - frenzy, growing pains, and key milestones by ChinAI
How I think about Codex by Gabriel Chua
The Cost of staying by Amy Tam
Open models in perpetual catch-up by Nathan Lambert (plus our interview with him)
Follow us on 🎥 YouTube Twitter Hugging Face 🤗
Twitter Library
20 Awesome Github Repos to Build OpenClaw-Style Agents

News from the usual suspects
Meta & NVIDIA – “Full-Stack, Full-Throttle”
Meta is locking arms with NVIDIA in a multiyear pact to build hyperscale AI factories powered by Grace CPUs, millions of Blackwell and Rubin GPUs, and Spectrum-X networking. From training frontier models to running inference for billions, it’s a unified, energy-tuned architecture – with Confidential Computing safeguarding WhatsApp’s AI features. Industrial-scale AI, now with a privacy footnote.Pentagon vs. Anthropic – “Lawful Purposes, Meet Guardrails”
The Pentagon is reportedly close to cutting ties with Anthropic, frustrated by limits on how Claude can be used. Anthropic insists its AI must not enable mass domestic surveillance or fully autonomous weapons; the Defense Department wants latitude for “all lawful purposes.” If labeled a supply chain risk, contractors may be forced to drop Anthropic. Responsible AI just met realpolitik.ASML – “1,000 Watts, 330 Wafers, One Big Moat”
ASML researchers say they’ve pushed EUV source power to 1,000W (from ~600W), a step that could raise tool throughput to ~330 wafers/hour by 2030 (from ~220) and deliver up to 50% more chips as exposure times shrink. The engineering: ~100,000 tin droplets/second plus a two-burst laser “shaping” method to form hotter, brighter plasma – keeping would-be US and China challengers in the rearview mirror.Congrats to ggml.ai and Hugging Face →
Models Highlight
Causal-JEPA: Learning World Models through Object-Level Latent Interventions
Injects object-level masking that induces latent counterfactual structure during training, embedding a causal inductive bias directly into world models.
Important because it shifts prediction toward interaction reasoning required for planning and control →read the paperKimi K2.5: Visual Agentic Intelligence
Trains a native multimodal model with Parallel-Agent Reinforcement Learning that learns to orchestrate up to 100 subagents and optimize critical-path latency.
Important because parallel orchestration becomes a learned capability inside the model rather than external scaffolding →read the paperGLM-5: from Vibe Coding to Agentic Engineering
Scales long-horizon reinforcement learning with asynchronous training infrastructure to support autonomous multi-step engineering tasks.
Important because it trains models for sustained workflow execution rather than isolated responses →read the paperQwen3.5: Towards Native Multimodal Agents
Combines sparse MoE, hybrid attention, early text–vision fusion, and large-scale RL environment scaling into an architecture built for multimodal agent behavior.
Important because multimodality and tool use are native design constraints rather than add-ons →read the paperWorld Action Models are Zero-shot Policies
Unifies video prediction and action generation into a single generative dynamics model that functions as a zero-shot policy.
Important because it collapses world modeling and control into the same backbone →read the paperComputer-Using World Model
Learns UI state transitions to simulate software actions before execution, enabling counterfactual search in digital environments.
Important because it turns computer use into model-based planning instead of reactive prompting →read the paperGemini 3.1 Pro
Advances core reasoning performance on abstract generalization benchmarks and strengthens the baseline intelligence powering agentic workflows across Google’s ecosystem.
Important because it represents a push on underlying reasoning capacity that upstream systems such as Deep Think and enterprise agents rely on →read the paper