

FOD#123: The Master Algorithm?
exploring Tensor logic, nanochat, Omni chat and all other amazing AI developments of the week

This Week in Turing Post:
Wednesday / AI 101 series: Neuro-symbolic AI
Friday / AI Literacy: co-create with AI
Our news digest is always free. Upgrade to receive our deep dives in full, directly into your inbox.
Apologies for the delay – the whole internet was not super functional yesterday.
My path into machine learning started with the book The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World, written by Pedro Domingos in 2015. If you read Pedro Domingos on Twitter, you might hate him – he’s famously provocative and doesn’t care much about hurting feelings.
Recently, I went to IA Summit organized by Madrona, one of the most forward-thinking VC funds focused on AI. And there he was, Pedro Domingos himself, challenging speakers with sharp questions. “He might tell me off right on the spot,” I thought – but curiosity overpowered any assumptions, and I asked if I could sit next to him. “You know,” I said, “my ML journey started with your book.” It might have melted his heart –I’m not sure – but we had a great conversation, discussing reasoning machines, reinforcement learning, and of course, I asked if he was finally working on the Master Algorithm I’d been waiting for since reading his book.
“I’m actually very close to publishing it,” he said.
And so, last week, the world was quietly introduced to Tensor Logic – the paper Domingos believes is the closest realization of the Master Algorithm yet. It slipped under the radar, and that’s exactly why I want to draw attention to it.
While the title sounds abstract, Tensor Logic is a serious attempt to do what Domingos has promised for a decade: to find a common language for all of AI. His argument is simple and radical – neural networks, symbolic logic, and probabilistic reasoning are not different fields at all. They are the same operation written in different notations. Logical rules, he shows, can be expressed as Einstein summations over tensors. In this view, everything from transformers to Prolog programs to Bayesian networks can be built from a single primitive: the tensor equation.
If that sounds theoretical, it’s not. Domingos is proposing a new programming language for AI (and promises to open a repo soon) – one where both learning and reasoning live in the same algebra and run directly on GPUs. In Tensor Logic, a neural layer, a logical rule, and a probabilistic inference step all compile to the same structure. No Python scaffolding, no glue code between symbolic and neural components – just equations. It’s mathematically elegant and potentially a foundation for the next generation of AI infrastructure.
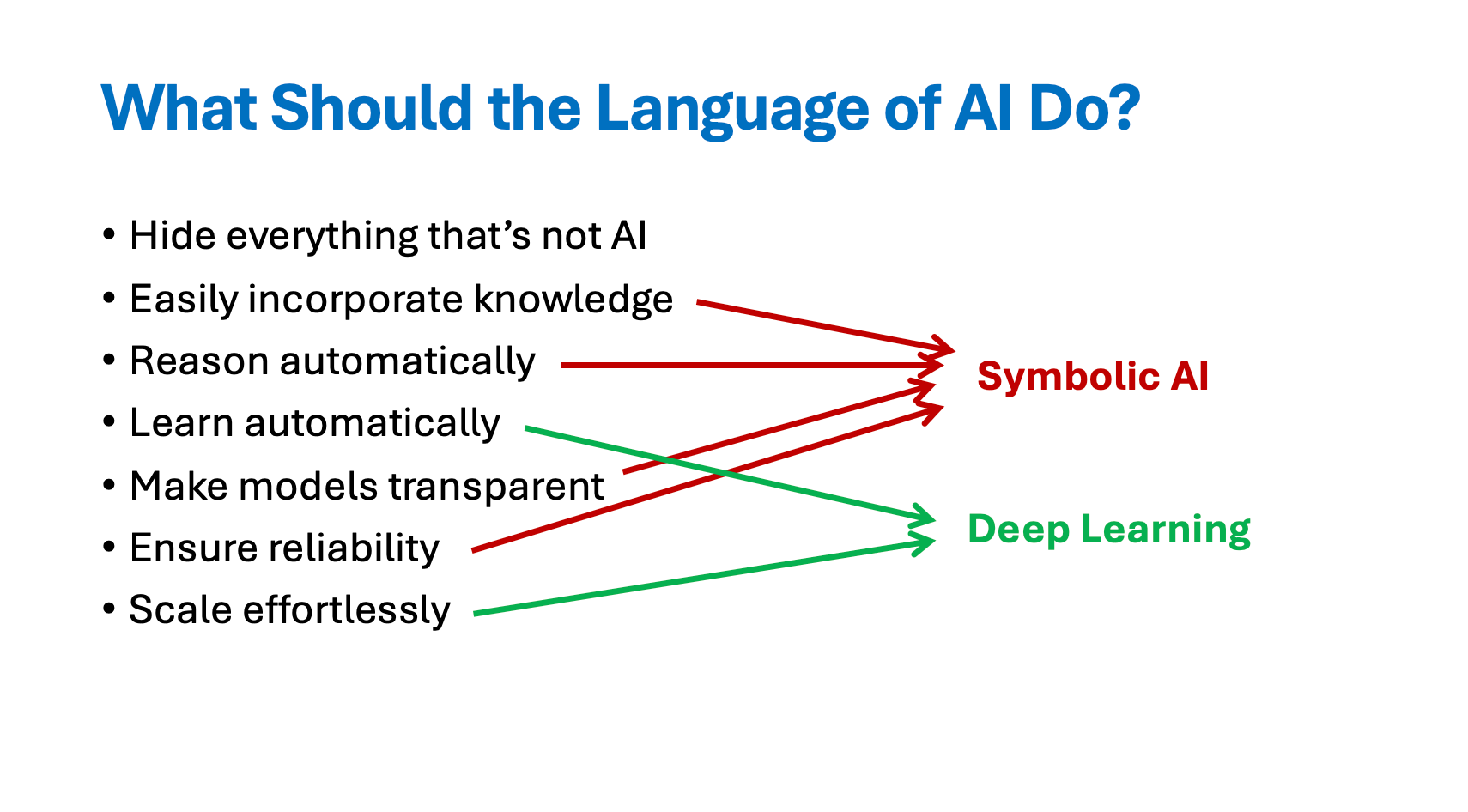
The most intriguing part is what he calls reasoning in embedding space. Reasoning in embedding space matters right now because it hits the nerve of where the field is stuck. In Tensor Logic, facts and rules live inside vector embeddings. At low “temperature,” the system behaves like pure logic – provable, deterministic, and free of hallucinations. As the temperature rises, reasoning becomes analogical: similar concepts borrow inferences from each other. This “logic-to-analogy” continuum could bridge the gap between the reliability of symbolic reasoning and the pattern recognition of LLMs.
That’s why this paper might become a big deal. Today’s LLMs are fluent imitators but clumsy reasoners. They produce text without a formal system of truth. Tensor Logic offers a way to give them one – a mathematical substrate for reasoning, not just stohastic pattern complition. Can it become to AI what calculus was to physics? We are yet to see. But it certainly worth exploring.
🤝 Want to scale your AV data workflows 10x faster?

Most AV teams can segment LiDAR and camera data, but struggle to iterate quickly, detect rare events, and scale workflows reliably. The teams that succeed combine curation, annotation, and model evaluation all in one place.
Encord is the universal data layer trusted by the world’s leading ADAS & AV teams, like Woven by Toyota and Zipline.
We recommend to join Encord’s LiDAR experts on Oct. 28 for a masterclass on how to:
Visualize and curate multimodal data, including LiDAR and radar
Automate 3D segmentation of obstacles with single-shot labeling and object tracking
Create robust, scalable pipelines for model training and evaluation
Join live or sign up below to catch the replay → SAVE YOUR SPOT
Topic 2: With so much out there, attention gets stretched too thin. This time, we are focusing on the overlooked topics in the conversation between Andrej Karpathy and Dwarkesh Patel. AGI Bubble and AI Aristocracy. Watch it here→
Links from the editorial:
The Master Algorithm (book)
Pedro Domingos (Twitter)
Tensor Logic: The Language of AI (paper and website with slides)
We are also reading/watching:
Talk with Jensen Huang on AI & the Next Frontier of Growth (video) where he says: “We went from 95% market share to 0%. I can’t imagine any policymaker thinking that’s a good idea… whatever policy we implemented caused America to lose one of the largest markets in the world to 0%”
“How China Built a Parallel AI Chip Universe in 18 Months” by AI Supremacy
Ringing Black Hole Confirms Einstein and Hawking’s Predictions by Simons Foundation
Follow us on 🎥 YouTube Twitter Hugging Face 🤗
Curated Collections – Learning is power

News from The Usual Suspects ©
The 𝕏 recommendation system is evolving very rapidly.
Hugging Face launches its Omni Chat. The initial version of HF Chat was somewhat disappointing – when I tried it, it didn’t work as expected. Since then, they’ve completely overhauled the design and functionality, turning it into a powerful router that intelligently selects the most suitable open-source model for each prompt. The new iteration looks great and performs impressively.
Anthropic has introduced Agent Skills, a modular way to enhance Claude’s capabilities for specific tasks like Excel work or adhering to brand guidelines. Skills are lightweight, portable folders containing code, resources, and instructions that Claude loads only when needed. Developers and teams can now create and manage custom skills across Claude apps, API, and Claude Code—bringing more structure and precision to AI workflows. Related blog by Simon Willison: Claude Skills are awesome, maybe a bigger deal than MCP
Amazing tutorial: Robot Learning → A Tutorial

Models to pay attention to
RTFM (Real-Time Frame Model)
DeepSeek-OCR: Contexts Optical Compression
Researchers from DeepSeek AI released DeepSeek-OCR, a vision-text model designed to integrate document understanding into LLMs efficiently. It introduces Contexts Optical Compression, supporting native resolutions from 512×512 to 1280×1280 and a dynamic “Gundam” mode. Prompts enable markdown conversion, layout parsing, OCR, and visual grounding. Running at ~2500 tokens/sec on A100-40G GPUs, it supports both vLLM and Transformers. The model emphasizes efficient visual-token compression and supports flash attention 2.0 for acceleration. It is open-sourced under MIT license and optimized for OCR-rich tasks across diverse visual layouts →GitHubFantastic (small) retrievers and how to train them: Mxbai-edge-colbert-v0 tech report
Researchers from Mixedbread AI and Waseda University introduced mxbai-edge-colbert-v0, two late-interaction ColBERT models with 17M and 32M parameters. These outperform ColBERTv2 on BEIR despite lower embedding dimensions (48/64). Using ModernBERT backbones, multi-stage training (contrastive pre-training, fine-tuning, distillation), and optimized ablations, the 17M model supports 32k contexts, runs efficiently on CPU, and stores vectors with 2.5× less memory. It achieves 0.6405 NDCG@10 on NanoBEIR →read the paperQwen3Guard technical report
Researchers from Qwen introduced Qwen3Guard, a multilingual safety moderation model available in 0.6B, 4B, and 8B sizes, supporting 119 languages. It includes Generative Qwen3Guard for tri-class safety classification (safe, controversial, unsafe) and Stream Qwen3Guard for token-level real-time moderation. Qwen3Guard-Gen achieves state-of-the-art F1 scores on 8 of 14 English benchmarks, surpasses larger models on multilingual tasks, and supports response refusal detection. Stream Qwen3Guard achieves near real-time latency with only ~2-point performance drop, enabling efficient streaming safety interventions →read the paperA2fm: An adaptive agent foundation model for tool-aware hybrid reasoning
Researchers from OPPO developed A2FM, a 32B model integrating three execution modes—agentic (tool-using), reasoning (chain-of-thought), and instant (direct answers). It uses a route-then-align strategy and introduces Adaptive Policy Optimization (APO) for efficiency-accuracy trade-offs. A2FM achieves 13.4% on BrowseComp, 70.4% on AIME25, and 16.7% on HLE. It surpasses 32B peers in cost efficiency—$0.00487 per correct answer—cutting cost by 45.2% vs reasoning mode. It ranks top across agentic, reasoning, and general benchmarks →read the paper