

AI 101: DeepSeek mHC: Breaking the Architectural Limits of Deep Learning
your full guide to how residual connections started, how they evolved, and why DeepSeek’s Manifold-Constrained Hyper-Connections (mHC) are so important now
At the very end of 2025, on December 31, DeepSeek released a paper titled “mHC: Manifold-Constrained Hyper-Connections,” and once again shook the AI community. This time, not with a new model, but with a mathematical wake-up call:
We are running into architectural limits.
For a decade, the “just add more layers” strategy has relied on a single architectural crutch: the residual connection. It is the reason GPT-4 exists and the reason Transformers train at all. But it is also a constraint. By forcing every layer to preserve access to the original input, we implicitly limit how much the network can transform information. We trade expressivity for stability, and at massive scales this trade-off is becoming a bottleneck.
DeepSeek’s contribution is a proposal to rewrite the physics of the neural network. By moving from simple addition, as used in residuals, to geometric constraints defined on manifolds, they show that it is possible to build deep, stable networks without the safety net we have relied on since 2015.
What follows is the story of how we moved from patching signal leaks to engineering systems that conserve information by design, and why it matters so much.
In today’s episode, we will cover:
The 30-Year War Against Vanishing Signals
How It All Began
From Residuals to LSTM Memory
The Second Stage of Evolution: ResNets and DenseNets
Transformers and Residual Connections
What Are Hyper-Connections (and the hidden drawback)
The DeepSeek move: constrain the chaos instead of fighting it
How do mHC work?
Performance gains
Not without limitations
Conclusion: what to do next?
Sources and further reading
The 30-Year War Against Vanishing Signals
How It All Began
To understand why mHC is a breakthrough, we have to understand the fear that has driven AI architecture for three decades: the fear of losing the signal.
This fear materialized as soon as researchers tried to build deep. In recurrent systems, where signals must propagate backward through many time steps, an unprotected error signal faces a mathematical gauntlet. It either decays to zero, causing the network to forget, or blows up exponentially, causing chaos.
In 1991, Sepp Hochreiter (under Jürgen Schmidhuber’s supervision) formalized the solution while working on recurrent neural networks. His core insight was simple: instead of completely rewriting the network’s state at every step, the system should just add a small update to the existing value.
He engineered a “clean identity path” – a protected lane where information could flow without distortion. By fixing a self-connection weight to exactly 1.0, he created what he called constant error flow. The signal could finally survive the journey backward. But this survival came with a strict architectural condition: the weight had to be exactly 1.0. Shift that value even slightly, and the stability guarantee vanishes.
This established the foundational rule that has governed deep learning ever since: the safest way to preserve a learning signal is to protect it with additive updates.
From Residuals to LSTM Memory
In 1997, Hochreiter and Schmidhuber operationalized this survival strategy into the Long Short-Term Memory (LSTM) network. They built a dedicated structure to house that fragile 1.0 weight: the Constant Error Carousel.
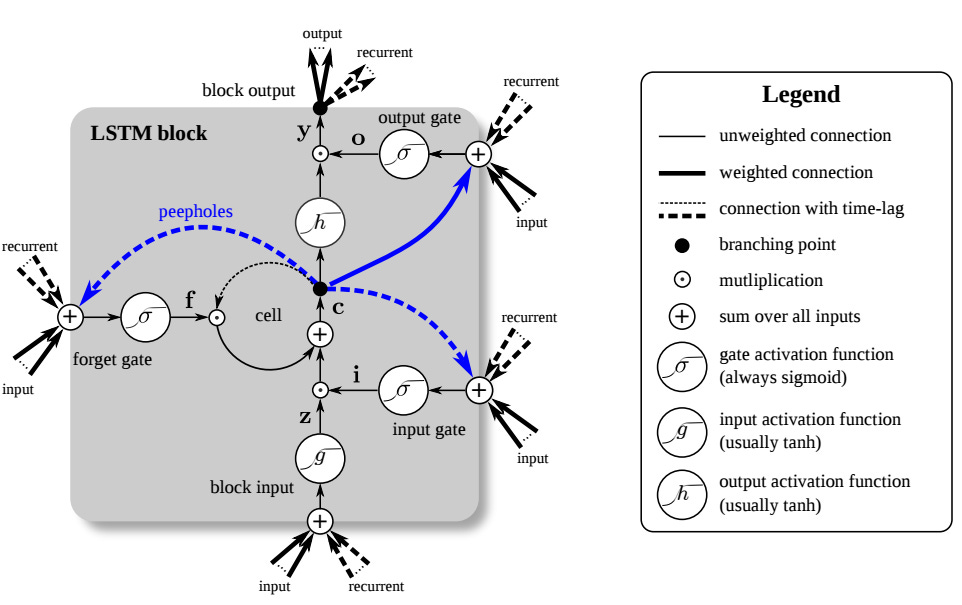
Think of the Carousel as a protected loop – a “safe room” within the architecture. While the rest of the network churned and transformed data, the Carousel allowed the gradient to cycle indefinitely without distortion. It was a recurrent residual connection in its purest form, enabling memory to persist across thousands of steps.
Later, the architecture evolved to include Forget Gates. This turned the rigid safety net into a controllable valve. The model could now make a choice: keep the valve open (weight near 1.0) to preserve history, or shut it (weight near 0) to reset the context. It was the first step toward managing the flow of information rather than just blindly forcing it through.
This distinction is critical because, as researcher Alex Graves later demonstrated, time is depth. When you unfold an LSTM through time, it becomes indistinguishable from a very deep feed-forward network. The massive success of LSTMs proved a hypothesis that would define the next two decades of AI: Depth itself was never the killer. Signal loss was.
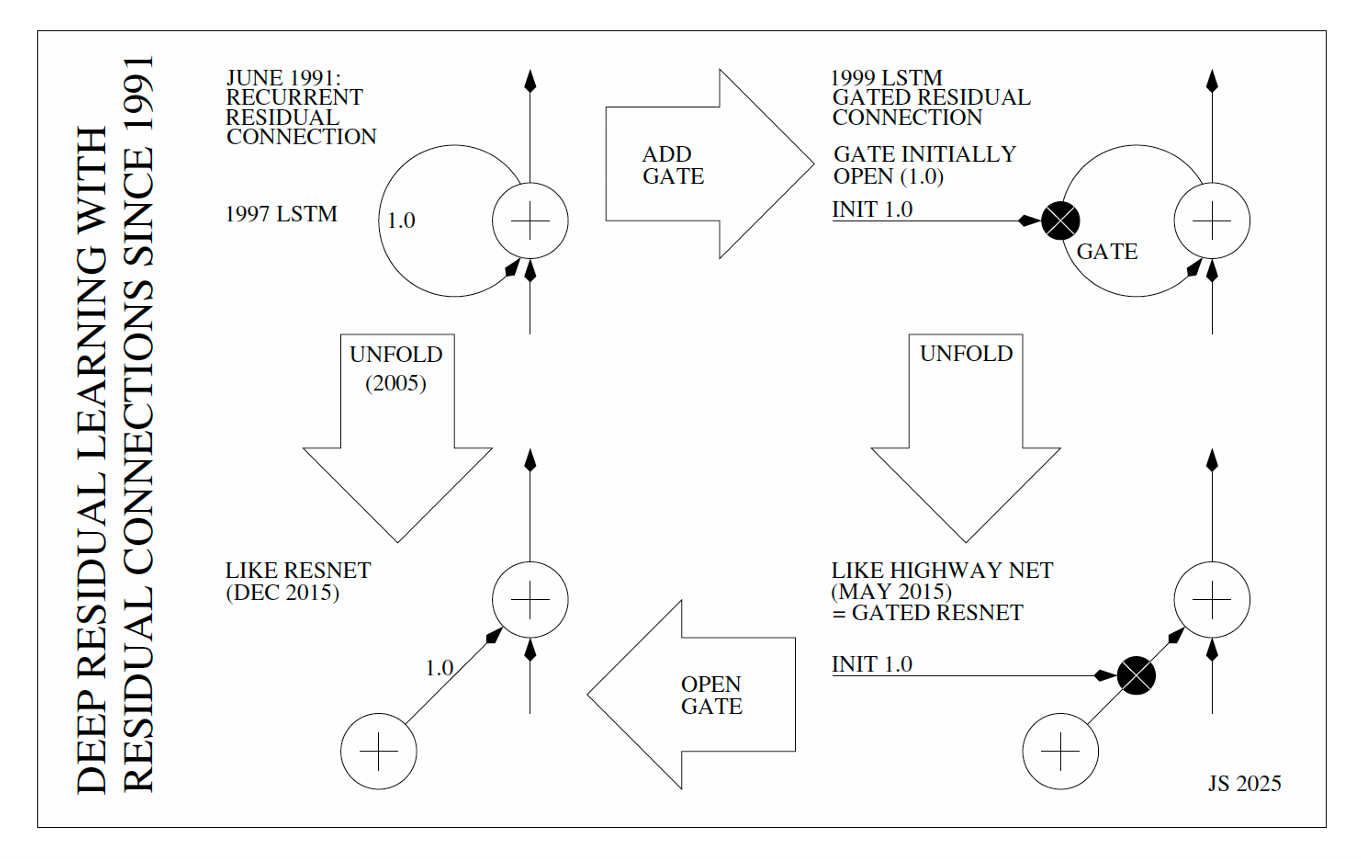
The Second Stage of Evolution: ResNets and DenseNets
Two decades after Hochreiter’s insight, the battle against signal loss migrated from the dimension of time (RNNs) to the dimension of depth (Feed-Forward Networks). The goal remained the same: prevent the signal from dying as it traveled through the architecture. We were ready to build the skyscrapers of intelligence, but we still lacked the steel.
What did researchers come up with? →
The framing of residual connections as both enabler and bottlenck is spot on. That constant weight of 1.0 being the core constraint is someting most people overlook when celebrating ResNets. I've been curious how mHC handles the expressivity vs stability tradeoff in practice, especially at scales where convergence gets finicky. If DeepSeek's approach really allows deeper transformations without blowup, it could reshape how we think about model capacity.