

A Weekly AI Digest → What Happens When Agents Start Building Their Own World?
How recursive improvement, agent infrastructure, and new learning paradigms are reshaping AI
This week we saw progress in recursive self-improvement, new ways to train agents, growing discussions about responsibility in agentic systems, and a deeper look at how future AI may learn from the world itself rather than from text alone. There is a lot to discuss ‒ from AI systems that participate in their own improvement loops to the infrastructure that makes agents useful in practice. Let’s see →
1. Recursive Self-Improvement: From Science Fiction to Engineering
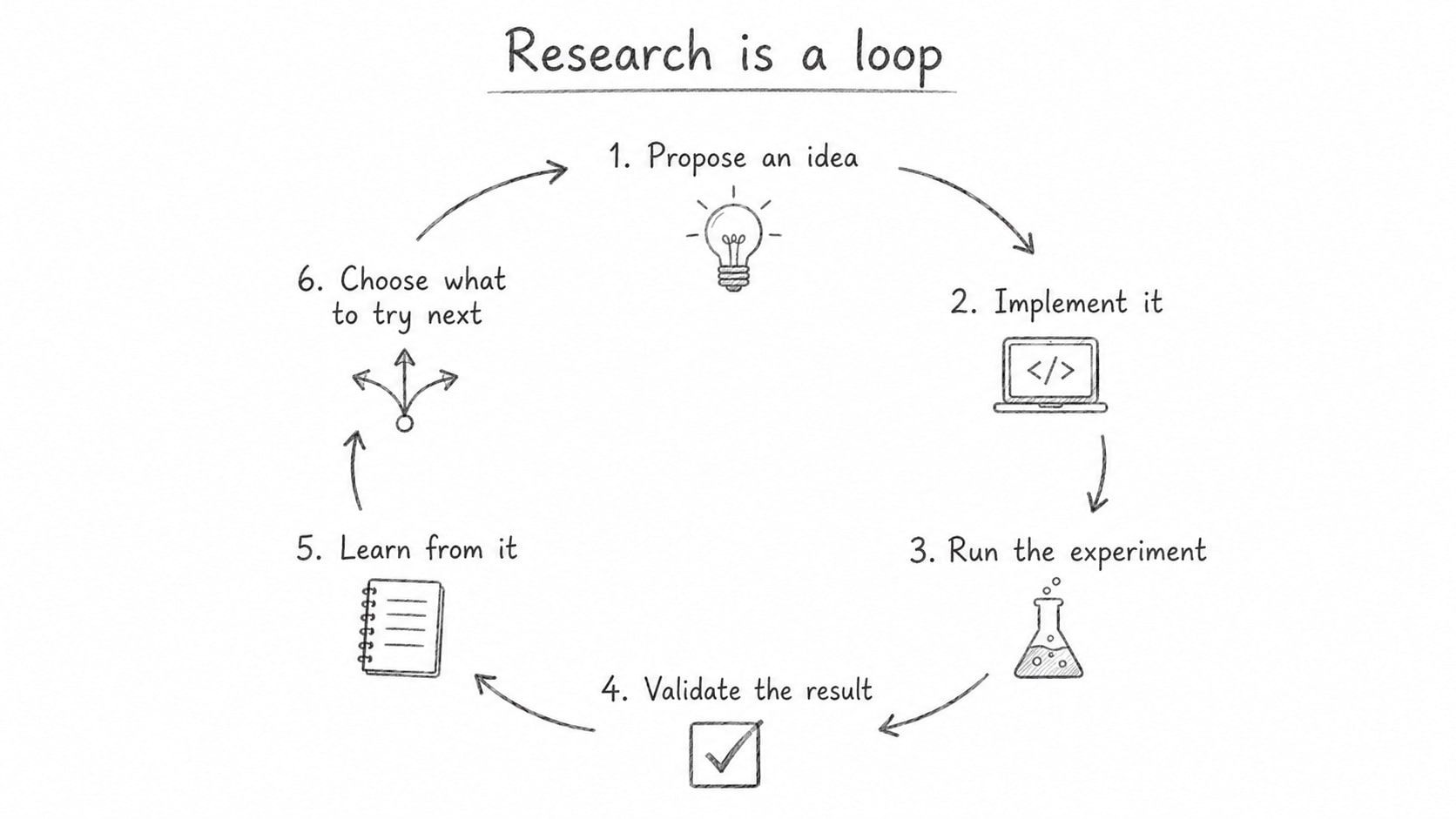
For years, recursive self-improvement was discussed as a distant possibility. AI improves AI, which improves AI again. This week, we explored what recursive self-improvement actually looks like in practice. It works as an engineering loop: propose → implement → test → evaluate → learn → choose the next step.
This means AI can now participate in parts of its own improvement process: writing code, designing experiments, analyzing outputs, and suggesting new iterations. But the hardest thing is still verification. Who decides whether the improvement is real? Without reliable evaluation, recursive improvement becomes just recursive noise.
2. Responsible AI Changes in the Agent Era
Responsible AI was mostly built for a world where models answer questions. Agents are different. They plan, use tools, remember context, and act across many steps.
This changes the risk landscape. The main question transforms into “What happens when the system takes action, affects other systems, and compounds small errors over time?”
The agent era needs responsibility at the workflow level: monitoring, permissions, audit trails, sandboxing, and evaluations that test behavior across long-horizon tasks.
Also, I chated with Sarah Bird who is CPO of Responsible AI at Microsoft. It was really insightful and if you are interested in the topic, I encourage you to check our this interview.
3. JEPA and the Return of World Models
JEPA (Joint Embedding Predictive Architecture) points to a different path for AI learning. Instead of predicting every token or pixel, Joint Embedding Predictive Architectures learn by predicting abstract representations.
This really matter so much, because intelligence may require more than surface-level prediction. Humans do not reconstruct every sensory detail; we build compressed models of how the world works. JEPA is important because it asks whether future AI systems should learn less like autocomplete and more like world-model builders.
In the article you’ll find a breakdown of different JEPA types and the general workflow patterns.
4. RL Training Tools for Agents
Training agents requires much more than prompting a model. It needs environments, rewards, verifiers, tool-use traces, memory, and feedback loops.
In this case, RL training tools help turn agent behavior into something measurable and improvable. The stack is starting to look less like classic ML training and more like infrastructure for repeated interaction. Check out the article to get a list of very useful RL training tools.
5. Agent Toolkits: The Misunderstood Layer
Agent toolkits are often treated as simple API wrappers. But in practice, they define what agents can actually do.
The real challenge is not only connecting a model to tools. It is managing execution, state, permissions, failures, retries, and verification. Better models matter, but reliable tool use may decide which agents become useful in real workflows.
And this is the bigger pattern: the frontier is moving from isolated intelligence to systems around intelligence.
6. Who owns the reasoning loop?
I talked about exactly this in my solo segment for O’Reilly’s. In coding, in cybersecurity, in medicine, in science, the same question keeps appearing. Where does the model act? Who controls the tools? Who owns the feedback? Who decides when the loop is safe enough to run? Check it out→