

🌐 #1: Mastering Open Source AI in 2026: Essential Decisions for Builders
We start the new series on open source that moved from "catching-up" phase to "specialization and parity" phase

As promised, we’re starting a new series: Mastering Open Source AI in 2026.
Between December 2024 and January 2026, open models made a huge leap. In several areas, they reached parity with frontier proprietary models. In many others, they are still behind. What changed is not that open models suddenly became the best option. They became good enough in enough places that teams now have to think harder about their choices.
There is no doubt that open source is critically important for industry progress and transparency. The harder questions are these: if open models are still weaker, why should you consider choosing them anyway? When is it actually the right choice for you? When is it not?
This first episode sets the frame for the series. It outlines why we are talking about open source now: its layers, the current landscape, the importance of specialization, how it changes the economics of AI, the geopolitical dimension, and the kinds of decisions that follow. Alongside the written series, we will also dedicate our video interviews to the open source agenda, speaking with geographically diverse practitioners and researchers.
There is a lot to unpack here. By the end, you will have a practical framework for making open-source decisions and a clear sense of how to use it in ways that actually work for your goals. Let’s start.
Upgrade today with 10% OFF to receive every next episode in full
In today’s episode:
Why “open source” in AI is not a single category
The new landscape and the camps emerging inside it
The specialization era: different models for different jobs
The geopolitical dimension: how provenance and deployment interact with risk
What you need to decide this quarter
This series: what we will cover next
Why “open source” in AI is not a single category
Let’s talk a bit about terms.
Most people learned open source through software. You could inspect the code, run it, modify it, redistribute it, and build businesses on top. The “thing” that mattered was the source code.
Foundation models broke that simplicity. The “thing” that matters is not just code. It is also the trained parameters, the data mixture, the training pipeline, the evaluation regime, even system prompts, plus the safety policy and enforcement mechanisms. Some of those are open sometimes, and often they are not.
So the first reset is conceptual: in AI, openness is multi-layered, and different layers create different freedoms and different risks.
If you keep using “open source” as a single binary label, you will make bad procurement decisions, bad architecture decisions, and occasionally a bad legal decision that you discover only after you have traction.
The three layers of openness
Here is a working taxonomy that is useful for decision-making. It is not morally pure, but it is operational.
Open code
Tooling, training frameworks, inference engines, evaluation harnesses, orchestration layers, dataset utilities.
This is classic open source territory. It is also where a lot of long-term compounding happens, because tool ecosystems create adoption flywheels.
Open weights
You can download model parameters and run inference yourself.
This is the layer most people mean today when they say “open source AI,” even when the license is not actually a standard open source license. Open weights gives you optionality, but it also hands you operational responsibility.
Open training pipeline
Training data transparency, data governance, training recipes, hyperparameters, filtering, safety processes, and reproducible runs.
This is the rarest layer. It is also the layer that determines whether “open” is truly inspectable and auditable, which matters for some institutions and regulated contexts.
A model can be open at one layer and closed at two others. That is normal. Your job as a builder or decision-maker is to know which layer you actually need.
How this maps to real models (the list is not exhaustive)
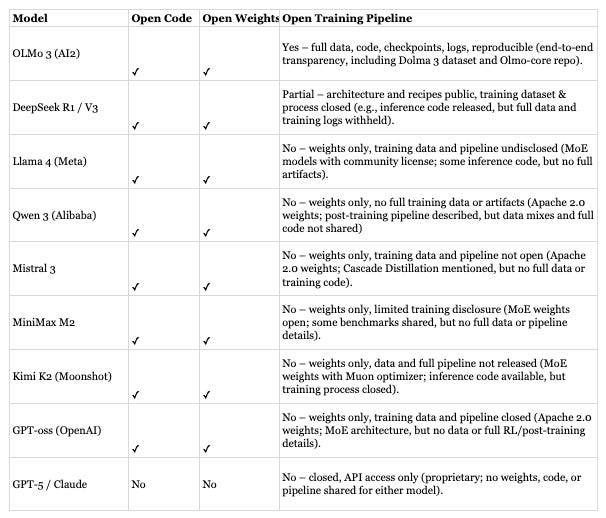
What changed over the past year is not that everything suddenly became open. It is that teams stopped treating openness as a single yes-or-no decision. Choices are now made layer by layer. Some teams choose open weights to control cost and deployment, even if training details remain opaque. Others accept smaller models because they need transparency and auditability. Many mix open tooling with closed models and see no contradiction in that. Once you look at openness this way, the old “open vs closed” framing stops being helpful. The real question is which parts of the system need to be open for what you are building, and which trade-offs you are willing to live with. We will come back to this throughout the series when we talk about choosing models under real constraints.
The new landscape and the camps emerging inside it
The first episode is free to read!